新しい研究論文は、Apple が他の企業が無視しているように見える AI の技術的な問題、具体的には、次のような低メモリのデバイスで大規模な言語モジュールを使用する方法について、実用的な解決策を持っていることを示しています。iPhone。
Apple がそう主張しているにもかかわらず、業界の裏側で同社は生成 AI に関して、リリースを急ぐのではなく、長期的な計画を継続していることを 2 度明らかにしました。ChatGPT クローン。最初の兆候はAIシステムを提案した研究論文でしたハグと呼ばれる、人間のデジタルアバターを生成します。
今、発見されたようにベンチャービート、2番目研究論文は、iPhone などの RAM が限られたデバイスに巨大なラージ言語モジュール (LLM) を展開するためのソリューションを提案しています。
の新しい紙これは「LLM in a flash: 限られたメモリでの効率的な大規模言語モデル推論」と呼ばれています。 Appleは、「モデルパラメータをフラッシュメモリに保存し、オンデマンドでDRAMに取り込むことで、利用可能なDRAM容量を超えるLLMを効率的に実行するという課題に取り組んでいる」と述べている。
そのため、LLM 全体をデバイス上に保存する必要がありますが、RAM 内での作業は、フラッシュ メモリを仮想メモリの一種として使用することで実現でき、macOS でメモリを大量に使用するタスクを実行する方法と似ています。
「このフラッシュメモリに基づいたフレームワーク内で、2 つの主要な技術を導入します」と研究論文では述べられています。 「まず、「ウィンドウ化」により、以前にアクティブ化されたニューロンを再利用することで、データ転送が戦略的に削減されます。次に、フラッシュ メモリのシーケンシャル データ アクセスの強度に合わせて調整された「行と列のバンドル」により、フラッシュ メモリから読み取られるデータ チャンクのサイズが増加します。 」
これが最終的に意味するのは、実質的にどのようなサイズの LLM も、メモリやストレージが限られたデバイスにも展開できるということです。これは、Apple がより多くのデバイスで、つまりより多くの方法で AI 機能を活用できることを意味します。
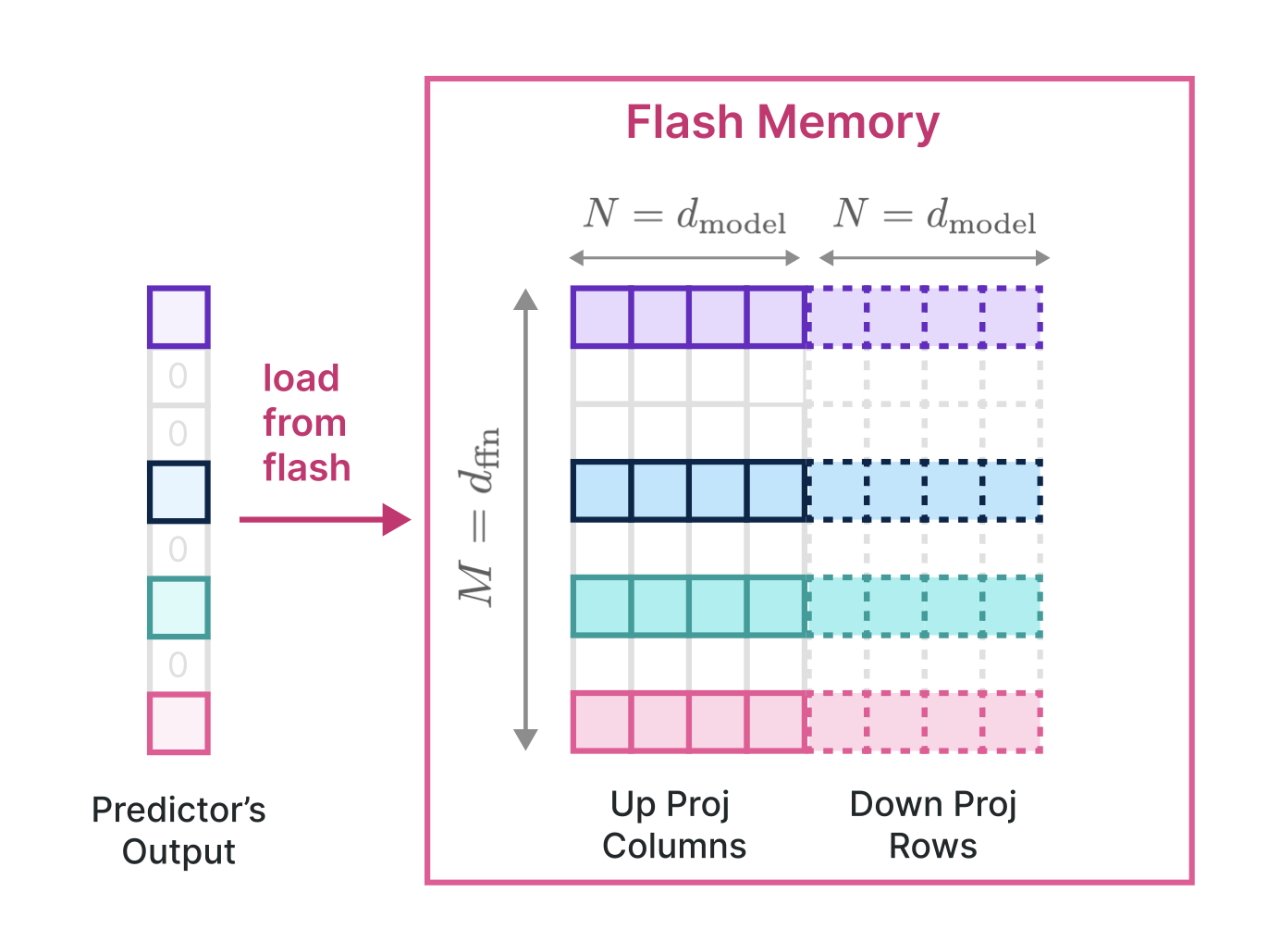 フラッシュ メモリからの LLM の読み取りの高速化を示す研究論文の詳細
フラッシュ メモリからの LLM の読み取りの高速化を示す研究論文の詳細
「我々の研究の実際的な成果は注目に値する」と研究論文は主張している。 「私たちは、利用可能な DRAM の最大 2 倍のサイズの LLM を実行できることを実証し、CPU では従来のロード方法と比較して 4 ~ 5 倍、GPU では 20 ~ 25 倍の推論速度の加速を達成しました。」
「このブレークスルーは、リソースが限られた環境に高度な LLM を導入する場合に特に重要であり、それによってその適用性とアクセシビリティが拡大します。」と続けています。
Apple は、HUGS の論文と同様に、この調査結果を公開しました。つまり、遅れを取るのではなく、業界全体の AI 機能の向上に実際に取り組んでいるのです。
これは、Apple のユーザーベースを考慮すると、同社は最も利益を得るAI がさらに主流になるにつれて。