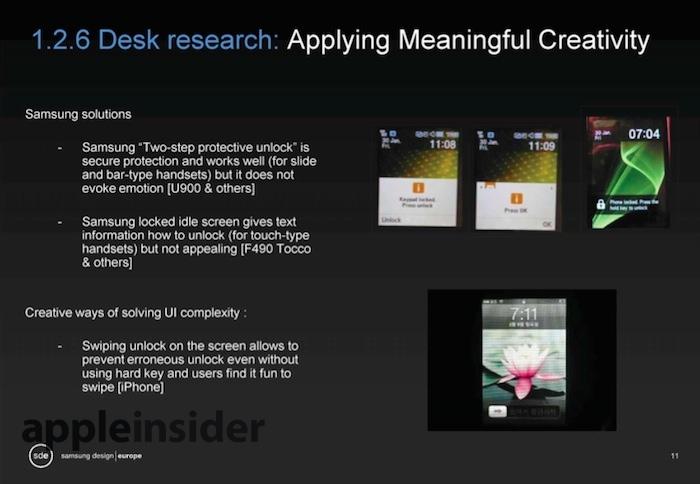
Appleは水曜日、Machine Learning Journalを通じて別の論文を発表したが、今回は差分プライバシー、つまり顧客の身元を隠しながらビッグデータを収集するために同社が採用している技術のテーマを扱っている。
Apple は、中央ではなく「ローカル」の差分プライバシーを利用しています。紙と説明します。これは、データがアップロードされた後ではなく、その前に個人のデバイスで「ノイズ」が生成され、完全に正確な情報が企業のサーバーを通過しないことを意味します。
Appleによれば、「多くの人がデータを提出すると、追加されたノイズが平均化され、意味のある情報が現れる」という。
同社はまた、このテクノロジーのオプトインの性質や、情報がアップロードされるとIPアドレスやレコード間のリンクが自動的に削除されるなどのその他の安全策も宣伝している。
「現時点では、例えば絵文字レコードとSafari Webドメインレコードが同じユーザーからのものであるかどうかを区別することはできません」と論文は続けている。 「記録は統計を計算するために処理されます。これらの集計された統計は、Apple の関連チームと社内で共有されます。」
差分プライバシーの使用例には、人気の絵文字の発見などがあると言われています。リソースを大量に消費する Web サイトの特定、略語、スラング、トレンドの単語、外来語を学習することでキーボードの自動修正を改善します。
このテクノロジーは、特に最近の研究で Apple のアプローチが依然として収集を続けていると主張して以来、時々物議を醸すことが判明しました。特定のデータが多すぎる。 Appleはその方法論と結論に異議を唱えた。